簡單回顧
介紹regularization之前,必須要了解什麼是overfitting。在之前的章節或多或少都有提到overfitting這號人物,那他為什麼那麼常被提到呢?如果你有訓練過模型,相信對它並不陌生。在訓練的時候,經常會出現overfitting的情況,regularization就是用來解決它的方法。
Overfitting
最右邊那張圖就是overfitting的狀況,顧名思義就是過度學習,對於訓練資料可以完美的做分類,但是如果有一筆新的資料可能會被分錯。
舉一個簡單的例子,平時上課不認真學生在拼指考時,不懂得舉一反三,就算只是一直寫考古題,也只能把寫過的考題答對,但如果有新的題型出現,可能就會考得很差。
如果訓練資料的features太多,就會造成訓練的hypothesis過於複雜,就會造成overfitting的情況。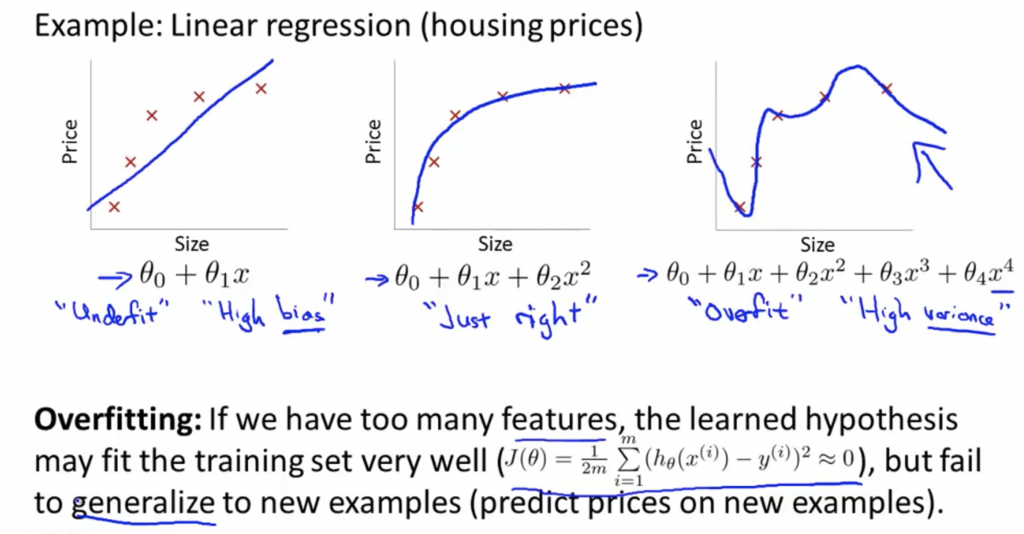
Regularization
左右兩張圖做比較可以發現,其實用到二次方就可以完美fit這些資料,所以我們現在就是要把其他高次方的參數拿掉,讓模型不會過於複雜,減少overfitting。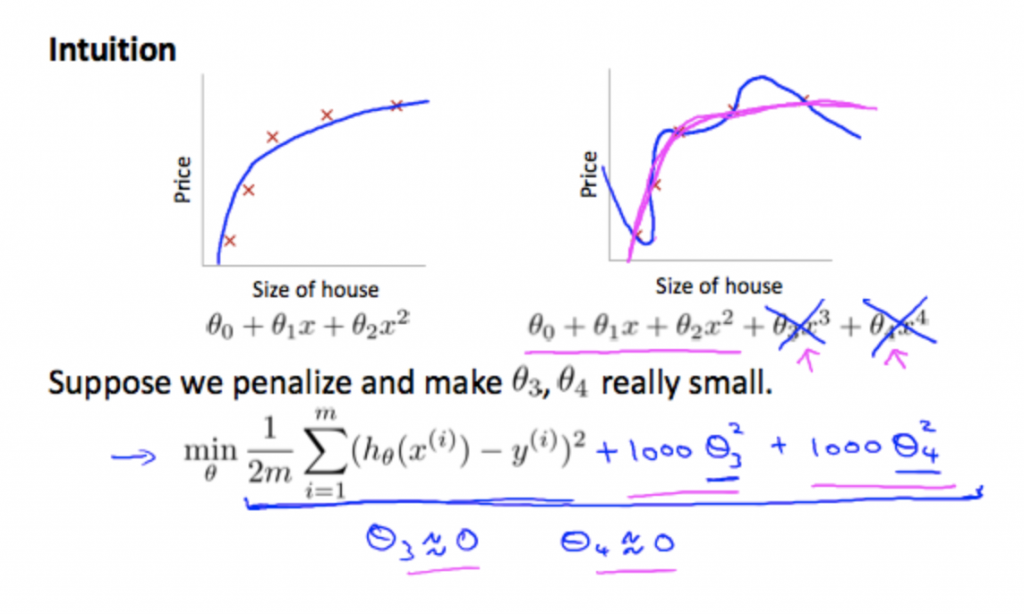
以linear regression來說,我們就是在原本的loss function後面再加上 λΣθ²

下面這張圖可以得知,參數做更新的狀況,跟之前所介紹的gradient descent類似,只是後面多了regularization那一項,將式子整理後可以得到,θ後面乘上(1-αλ/m),因為(1-αλ/m)< 1,所以可以減少原本的weight(指的是θ,大部分書籍都是用w)的影響,小的θ影響不大,如果本來就很大的θ,就可以有效受到抑制。



 iThome鐵人賽
iThome鐵人賽